What is Web Scraping? 웹 스크래핑이란?
"the process of using bots to extract content and data from a website."
웹 사이트의 데이터를 추출해 오는 것이다.
ref : https://www.imperva.com/learn/application-security/web-scraping-attack/
What Is Scraping | About Price & Web Scraping Tools | Imperva
Malicious web scraping is the extraction of data without permission of the website owner. Learn how to protect your content & revenue against web scraping tools
www.imperva.com
If you need to collect data, "Web Scraping" can be a time-saving technique.
However, Web scraping, as introduced in this post, is only feasible if the data on the websites is maintained in a specific format.
해당 글에서 설명하는 웹 스크래핑은 정보가 특정한 포맷으로 유지되어 있어야 활용이 가능하오니, 참고바란다.
Utilized Python Packages 사용한 파이썬 패키지
- requests
- BeautifulSoup (bs4)
import requests
from bs4 import BeautifulSoup
requests
- Key Features : HTTP methods
- Used Functions
- .get() : trying to get or retrieve data from a specified resource.
- res = requests.get(url, headers=headers)
- headers : your User-Agent
- res = requests.get(url, headers=headers)
- res.raise_for_status() : It will notify you that your code does not work.
- res.text() : It enables the confirmation of the process by text.
- .get() : trying to get or retrieve data from a specified resource.
ref : https://realpython.com/python-requests/#getting-started-with-pythons-requests-library
Python's Requests Library (Guide) – Real Python
In this tutorial on Python's Requests library, you'll see some of the most useful features that Requests has to offer as well as ways to customize and optimize those features. You'll learn how to use requests efficiently and stop requests to external servi
realpython.com
BeautifulSoup
- Key Features : parsing structured data
- Used Functions
- soup = BeautifulSoup([Target Content], "[The appropriate parser]") : reading your target content by the assigned parser.
- soup.find('body') : Find and extract the 'body' tag.
- soup.find_all('p') : Display all text content from all 'p' tags.
- If you're curious about the differences between 'body' and 'p' tags, learning about HTML tags is key!
This post provides information about HTML tags : https://jaermione.tistory.com/2 - 개인적으로 웹스크래핑 하는데 있어 HTML의 기본 구조에 대해 배우는 것이 큰 도움이 됐다.
- If you're curious about the differences between 'body' and 'p' tags, learning about HTML tags is key!
- soup.select_one('selector') : extract the element in specific path
- soup.select('a') : Display all text content from all 'a' tags.
- .attrs['href'] : Print the 'href' attribute value.
Learn HTML Basic Structure in Minutes: Tags & Elements / HTML 기본 구조 배우기(태그, 요소)
HTML means Hypertext Markup Language. This post aims to provide a basic introduction to using DevTools(Ctrl + Shift + i / F12), helping web development beginners gain a fundamental understanding of the tool. 본 포스팅의 목적은 개발자 도구의 [
jaermione.tistory.com
PRACTICE
Objective: Extract only the goods links from the given page!
import requests
from bs4 import BeautifulSoup
from lxml import etree
headers = {"User-Agent": ""} #put your information
url = 'https://~'
res = requests.get(url, headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
link=soup.find_all('a')
links=[]
for i in link:
if "href" and "name=\"goods_link\"" in str(i):
I=str(i).split(' ')
for a in I:
if "href" in str(a):
links.append(str(a).replace("\"","").replace("href=","https:"))
print(links)
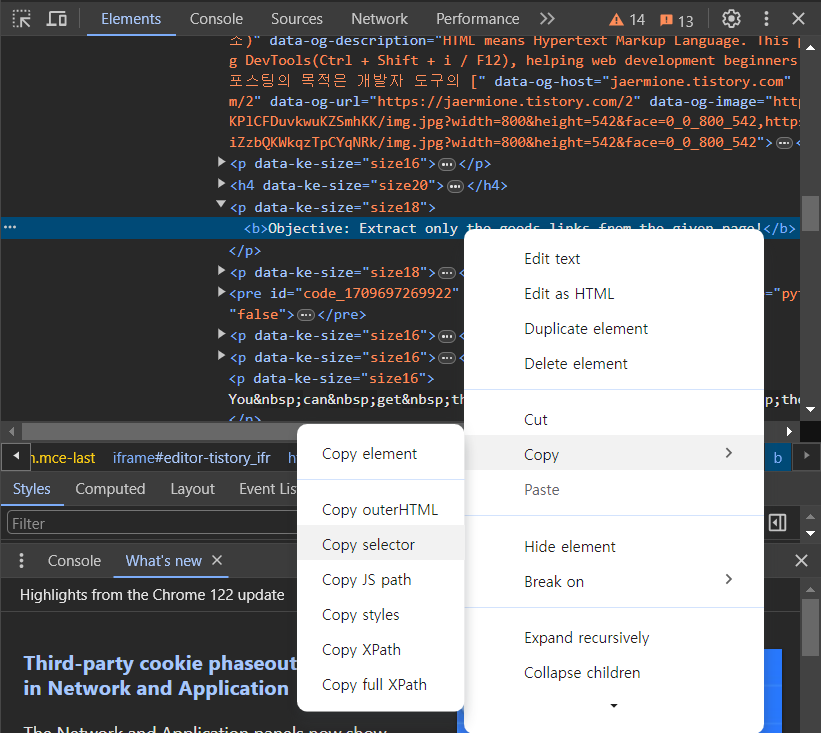
If you want to work on a specific section, you can use .select_one('selector') as shown below.
You can get the path by copying the selector from the DevTools.
특정 section에서 값 추출하고 싶으면, .select_one('selector') 이용해서 copy selector하는게 편하다.
import requests
from bs4 import BeautifulSoup
from lxml import etree
headers = {"User-Agent": ""} #put your information
url = 'https://~'
res = requests.get(url, headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
way2=soup.select_one("#product_list > div").find_all('a')
#way2=soup.select_one("#product_list > div").select('a')
for i in way2:
if 'app/goods' in str(i):
print('https:'+i.attrs['href'])
'Web' 카테고리의 다른 글
| Level Up Your HTML Skills: A Tistory Devtools Deep Dive / 티스토리 HTML 태그 분석하기 (0) | 2024.03.10 |
|---|---|
| Learn HTML Basic Structure in Minutes: Tags & Elements / HTML 기본 구조 배우기(태그, 요소) (0) | 2024.03.05 |

